Quite some time ago, I wrote a first article about how Mailbutler respects your privacy, which primarily focused on how we generally ensure protection of our users' privacy when designing the architecture of our system.
A few weeks ago, we introduced the Smart Assistant officially to Mailbutler. The new artificial intelligence-based features of Mailbutler introduce a new chapter for us as a company, but also for our users, who love the new capabilities Mailbutler provides to improve their everyday email communication. To better understand the content of this article, we have to go back to the end of 2022 when the actual work on the new Smart Assistant feature for Mailbutler started…
The foundation
At the end of 2022 the whole topic of artificial intelligence (AI) gained a lot of traction as OpenAI's GPT-3 model was utilized by more and more companies to enrich their products' functionality. While similar AI models were known and available in academia for a while, an easily accessible and at the same time very capable API to process textual data by an AI model made the decisive difference. The simple GPT-3 API provided by OpenAI made it very easy to build a prototype for AI-enriched functionality in just days, instead of months or years.
During that time, I also started to experiment with that API myself, and I built a first usable version of Mailbutler with AI capabilities, such as email summarization, automatic generation of tasks based on a received email, and generation of new emails based on short bullet lists. In December 2022 this first prototype became the foundation for what we started to call the Smart Assistant, which was then, a few months later, made available to our user base as part of the Early Access program. Just two months later, the Smart Assistant left this testing period and officially became part of the Mailbutler software suite.
As you can see from this wrap up of the last six to eight months, we moved very fast implementing artificial intelligence into our product, and we relied heavily on OpenAI's GPT-3 model to bring this super helpful tool into the hands of our users.
Many other companies took a very similar path and introduced AI-based features into their application. Most of them also rely on external services, such as OpenAI, to provide this kind of functionality; building your own AI models, collecting and managing input data, providing the computational resources, and constantly improving its functionality, is very resource and money intensive.
Long story short, AI features became more and more ubiquitous for most knowledge workers, and its usage has exploded in the last months.
Concerns
While millions of users worldwide already use these new AI-based tools in their favorite applications (or even use completely new applications, such as ChatGPT), the awareness of what happens inside of the black box is not properly developed yet. More and more companies are starting to restrict usage of AI-based tools. They are concerned that company internals, confidential information, or even security or financial data is processed, stored, or further used when using AI tools to provide answers based on content (such as spreadsheets, text documents, presentations, meeting minutes, phone or meeting recordings, and emails).
To be clear, AI tools can only do their work based on information that is provided by the user. The more information an AI model gets, the better its output can be. Thus, providing input data cannot be avoided. The goal must be to find methods which do not forfeit privacy for accuracy and vice versa.
Privacy by design
As I already explained when I discussed how Mailbutler respects your privacy, it's one of our core principles to ensure that our users' privacy is protected. This usually requires extra design and engineering effort, but we are convinced that this extra effort on our side pays off in the long run.
With regards to the Smart Assistant feature, it was clear from the beginning of the project that we wanted to send only a minimum amount of information to an external service, such as OpenAI's GPT-3 model.
Limiting the context
As a first step into this direction, we decided to only send information about the currently selected email to the AI model, instead of sending information about many, or even all, of our users' emails. We wanted to ensure that our users remained in control. We know that this is a compromise, as we are aware that sending more context, i.e. more emails, to an AI model, improves its generated output; but again, privacy is very deeply embedded in our company's foundation and values, and therefore we limited the context to the currently selected email.
Aside from limiting the amount of information that was being communicated, the next design decision was that we would only start sending information to the AI model when the user actively decided to use one of the Smart Assistant's features. We start sending the content of the currently selected email (or any other user-provided information) to OpenAI for processing and output generation only when you click on one of the Smart Assistant buttons in the Mailbutler Sidebar.
Limiting the content
But we did not stop there! Even in the content of a single email there might be information that is not meant to be processed by any external service. So, we wanted to pre-process the already limited information further.
The engineering problem is that we cannot simply remove information from the input data, i.e. our users' emails, because removing information would potentially result in less accurate results from the AI. Therefore, we had to take a different route, which is data anonymization: Instead of removing or redacting parts of an email before sending to OpenAI's API for processing, we rather replace potentially confidential, or at least sensitive, pieces of information with similar but random information of the same type and with the same amount of contained information.
Basic principle
The core idea behind this is that the AI model does not need to know that the recipient of an email is called, for example, Ernest Hemingway. Without losing any contextual information in the input, we can simply replace all occurrences of the name Ernest Hemingway with John Doe and only then forward the email as input data to the external AI model.
After the AI processes the input data and generates a suitable output following a certain requested operation, e.g. summarizing the content of that email, a final processing step would then replace all occurrences of John Doe (which is the name the AI would consider as the recipient of the email) back to the actual name Ernest Hemingway. The final "output of the output" which is presented to our users would still be consistent in terms of potentially sensitive information in the original email, but that information was never revealed to the external service provider or the utilized AI model.
First step: Basic anonymization
Following the aforementioned basic principle of data anonymization, we extended our AI processing pipeline with two corresponding modules:
- The first replaces occurrences of certain types of information in the input data, e.g. email addresses or web links, with corresponding random (dummy) information (real email addresses are replaced by random email addresses; real web links are replaced by random web links).
- The second module replaces occurrences of random/dummy information back to the original, potentially sensitive, information, so that the output for our own users corresponds to the original input and is therefore as accurate as it can be.
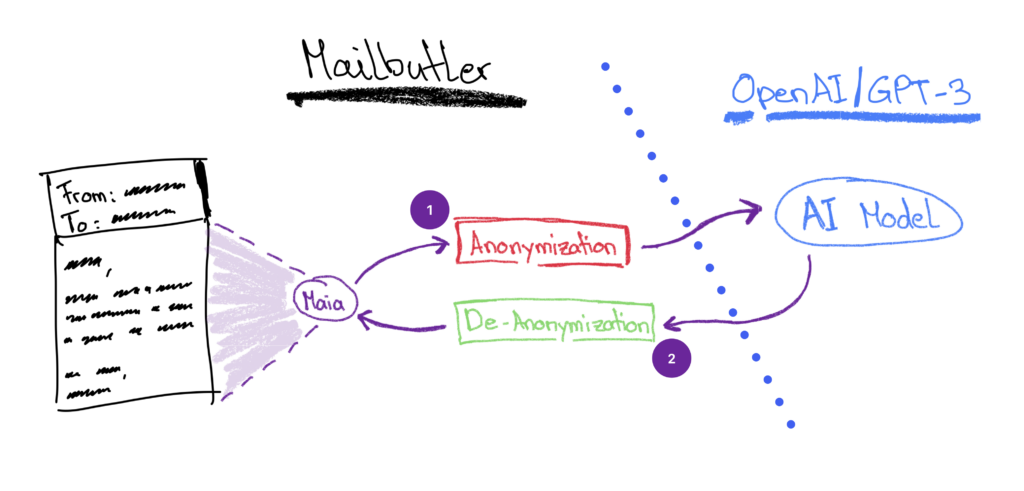
This is how the data (de-)anonymization modules are integrated into the Mailbutler system
The next steps
Since the Smart Assistant feature already contains the basic data processing pipeline as mentioned above, the next step for us is to further extend the functionality of the data anonymization modules. We're already working on extending the supported types of potentially sensitive information beyond email addresses and web links. We will soon also cover all sorts of financial information (e.g. credit card information or monetary numbers), names, references to documents (e.g. patents), and much more.
Moreover, we plan to build our own AI models internally, which will be capable of identifying sensitive information while also incorporating the context of an email to better decide what kind of information is sensitive and what isn't critical, but very useful, information for the accuracy of the output of the AI model.
Once again, we at Mailbutler want to take the required extra steps to respect our users' privacy as much as possible. I want to close this article by quoting myself, because what I said is relevant for all services, but especially important in the emerging world of AI:
Next time you use a service claiming to be “free”, think again what this actually means. How can a “free” service afford well-paid software engineers and other employees to work on this product?
Hopefully this article provided a solid overview of how important privacy protection is to us at Mailbutler and how deeply this principle is designed into our newest addition to the Mailbutler feature set, the Smart Assistant.
I look forward to reading your comments on this story, your follow-up questions on data privacy aspects, and also requests for more details about certain key aspects of the Mailbutler system and its inner workings.
As a small footnote to this article I want to disclose that the featured image at the top was AI-generated by Midjourney.